I am a PhD student in Statistics at University of Warwick, supervised by
Dr. Fanghui Liu,
Dr. Thomas Berrett,
and
Prof. Chenlei Leng.
I am interested in formal mathematical reasoning and theory-grounded algorithm design for post-training of LLMs. [CV]
Email: firstname.lastname@warwick.ac.uk
Publications
New LeanMarathon: Toward Reliable AI Co-Mathematicians through Long-Horizon Lean Autoformalization
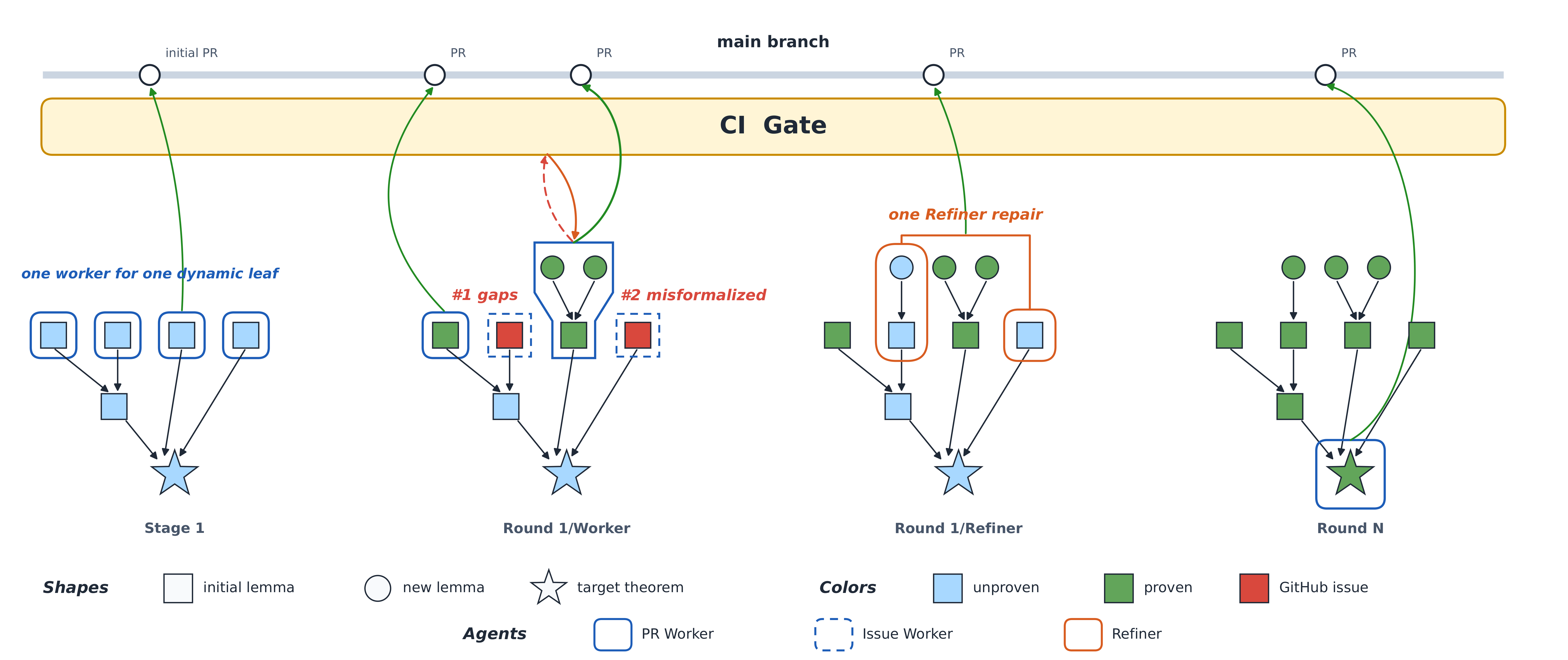
Yuanhe Zhang, Yuekai Sun, Taiji Suzuki, Jason D. Lee, Fanghui Liu
[PDF] [CLI]
New Statistical Learning Theory in Lean 4: Empirical Processes from Scratch
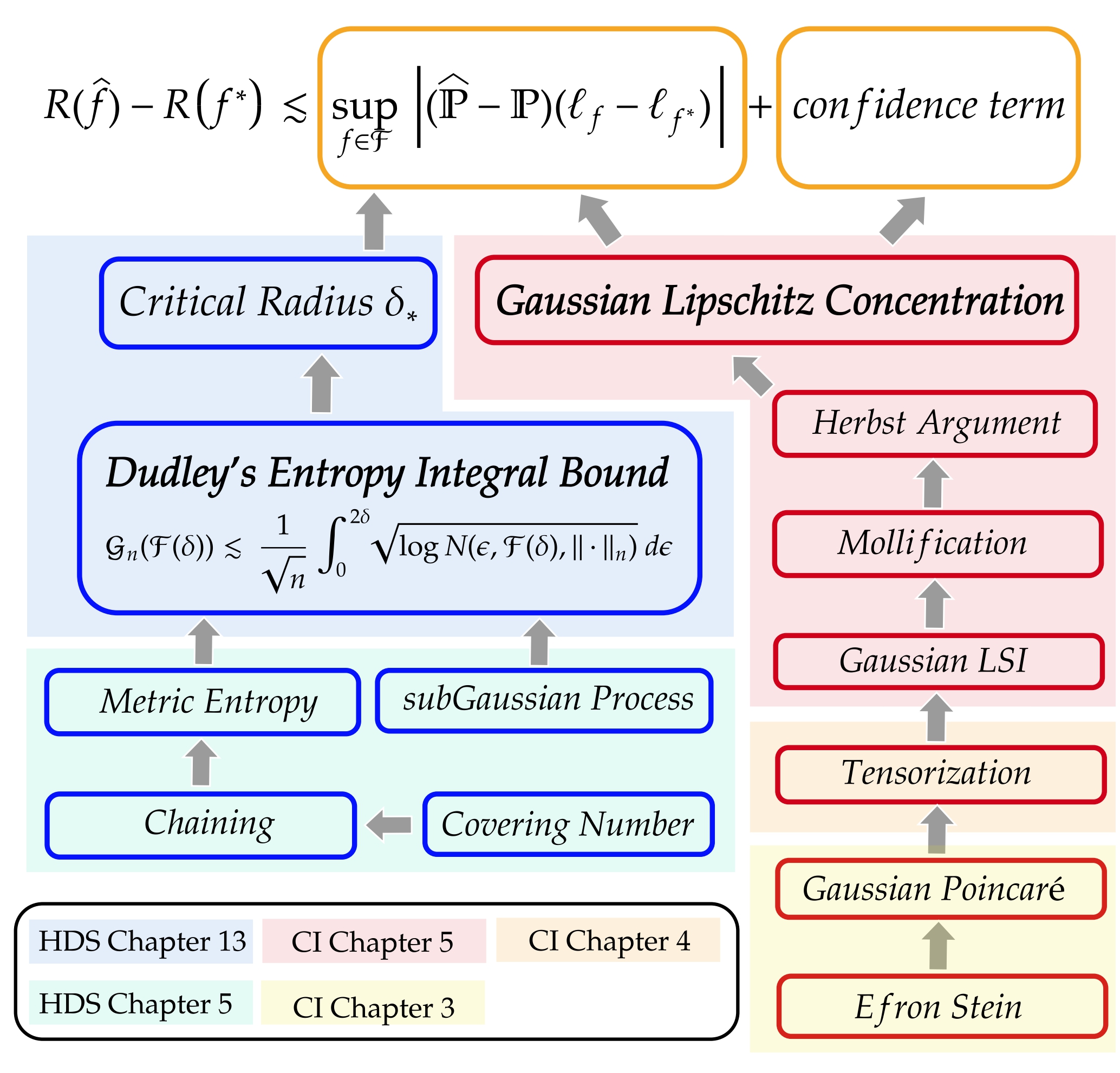
Yuanhe Zhang, Jason D. Lee, Fanghui Liu
International Conference on Machine Learning (ICML), 2026
[PDF] [Code] [HF Dataset] [Bibtex]
@article{zhang2026statistical,
title={Statistical Learning Theory in Lean 4: Empirical Processes from Scratch},
author={Zhang, Yuanhe and Lee, Jason D and Liu, Fanghui},
journal={arXiv preprint arXiv:2602.02285},
year={2026}
}
TLDR: We present the first large-scale Lean 4 formalization of statistical learning theory (SLT) grounded in empirical process theory from scratch. It covers scross High-Dimensional Gaussian Analysis Toolbox, Dudley’s Entropy Integral Bound, and sharp regression rates. Building upon our library, we present a high-quality Lean 4 training dataset for LLM's formal reasoning.
DAG-Math: Graph-of-Thought Guided Mathematical Reasoning in LLMs
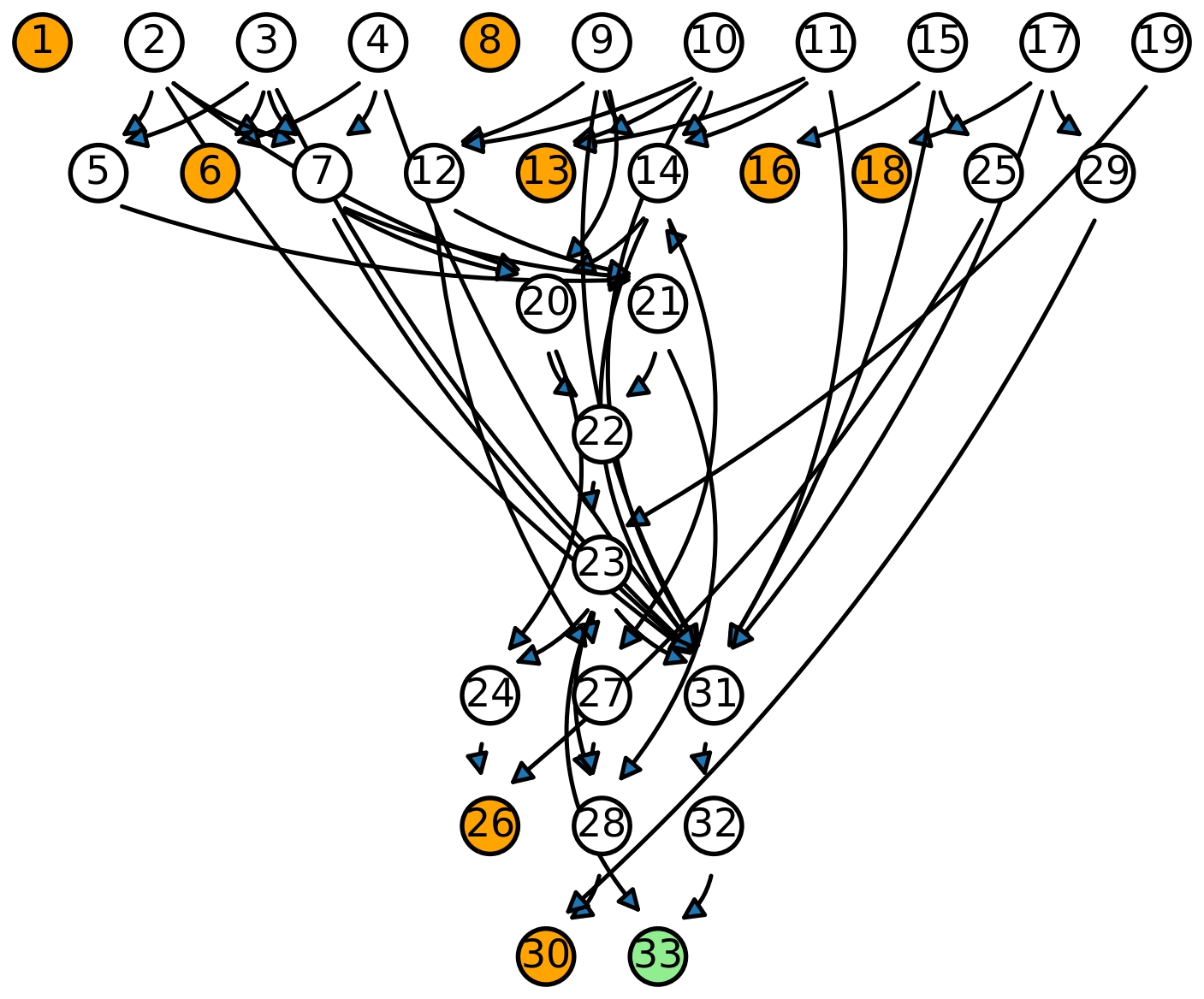
Yuanhe Zhang, Ilja Kuzborskij, Jason D. Lee, Chenlei Leng, Fanghui Liu
International Conference on Learning Representations (ICLR), 2026
[PDF] [Code] [HF Dataset] [Bibtex]
@article{zhang2025dag,
title={DAG-Math: Graph-Guided Mathematical Reasoning in LLMs},
author={Zhang, Yuanhe and Kuzborskij, Ilja and Lee, Jason D and Leng, Chenlei and Liu, Fanghui},
journal={arXiv preprint arXiv:2510.19842},
year={2025}
}
TLDR: We propose a new framework by modeling CoT as a rule-based stochastic process on directed acyclic graphs (DAGs), introduce the concept of logic closeness, and then precisely evaluates the mathematical reasoning ability of LLMs via the proposed DAG-MATH format.
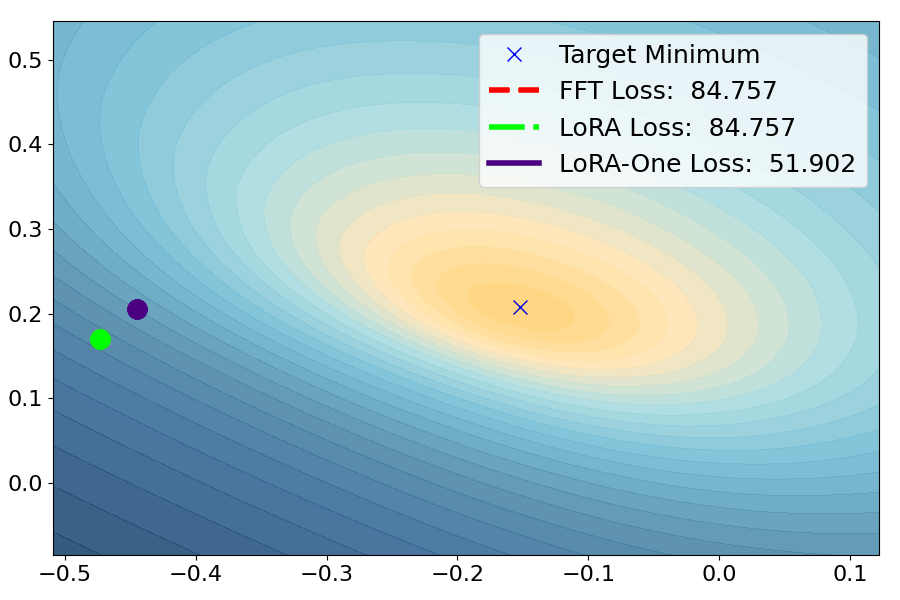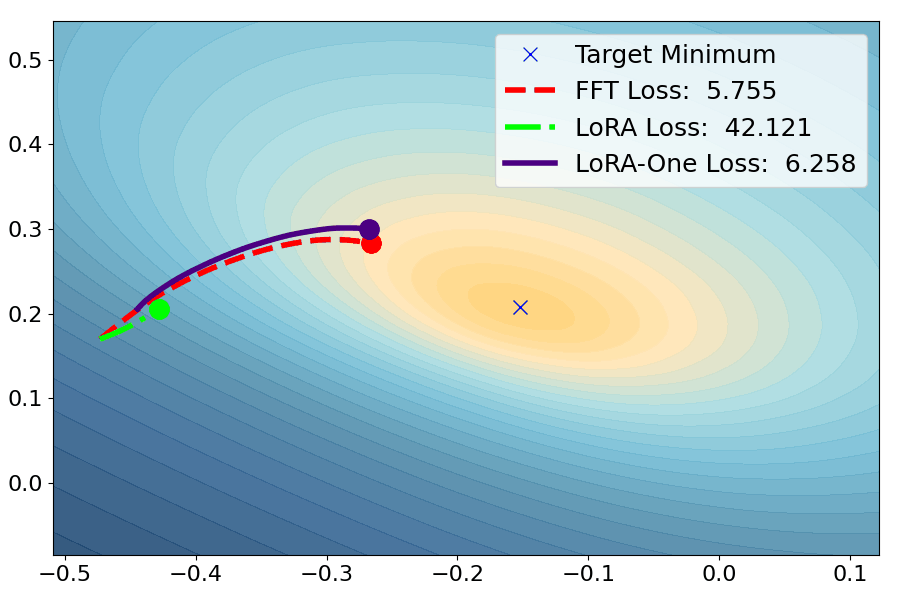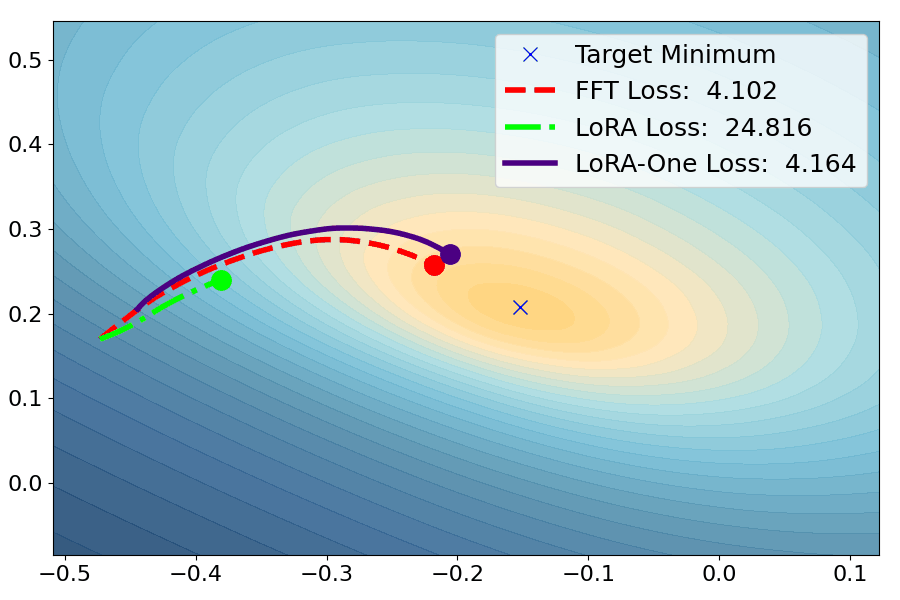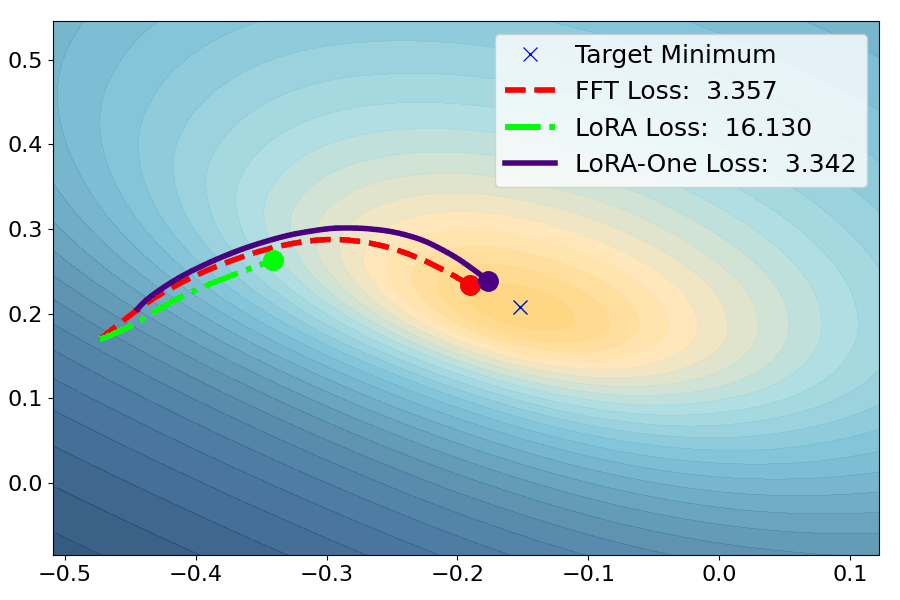
Yuanhe Zhang, Fanghui Liu, Yudong Chen
International Conference on Machine Learning (ICML), 2025 (Oral, top 120/12107=1.0% of papers).
[PDF] [Code] [Website] [Bibtex]
@InProceedings{pmlr-v267-zhang25ax,
title = {{L}o{RA}-One: One-Step Full Gradient Could Suffice for Fine-Tuning
Large Language Models, Provably and Efficiently},
author = {Zhang, Yuanhe and Liu, Fanghui and Chen, Yudong},
booktitle = {Proceedings of the 42nd International Conference on Machine Learning},
pages = {75513--75574},
year = {2025},
volume = {267},
series = {Proceedings of Machine Learning Research},
month = {13--19 Jul},
publisher = {PMLR},
url = {https://proceedings.mlr.press/v267/zhang25ax.html},
}
TLDR: We show how theory (from subspace alignment to gradient dynamics as well as preconditioners) contributes to fine-tuning algorithm design in practice.
Quasi-Bayes meets Vines
David Huk, Yuanhe Zhang, Ritabrata Dutta, Mark Steel
Advances in Neural Information Processing Systems (NeurIPS), 2024.
[PDF]
[Bibtex]
@article{huk2024quasi,
title={Quasi-Bayes meets Vines},
author={Huk, David and Zhang, Yuanhe and Dutta, Ritabrata and Steel, Mark},
journal={Advances in Neural Information Processing Systems},
volume={37},
pages={40359--40392},
year={2024}
}
Education
-
PhD in Statistics, University of Warwick
Supervised by Dr. Fanghui Liu, Dr. Thomas Berrett, and Prof. Chenlei Leng
2024-Current -
BSc MMathStat, University of Warwick
2020-2024